“A process cannot be understood by stopping it. Understanding must move with the flow of the process, must join it and flow with it.”
“Dune” by Frank Herbert
I have written a posting about my academic workflow, but I guess the visualization looked a little complicated. I have tried to do another visualization and this the current version. Note that I have replaced Mendeley with Papers, given that Papers has a few features I like (and a few I really, really hate — posting coming) and that I a bit … concerned about the recent acquisition of Mendeley by Elsevier. One good reason to remain flexible regarding one’s workflow, keep the information mobile (i.e., you can export it and import it somewhere else) and keep one’s eyes open.
But anyway, here is the workflow visualization:
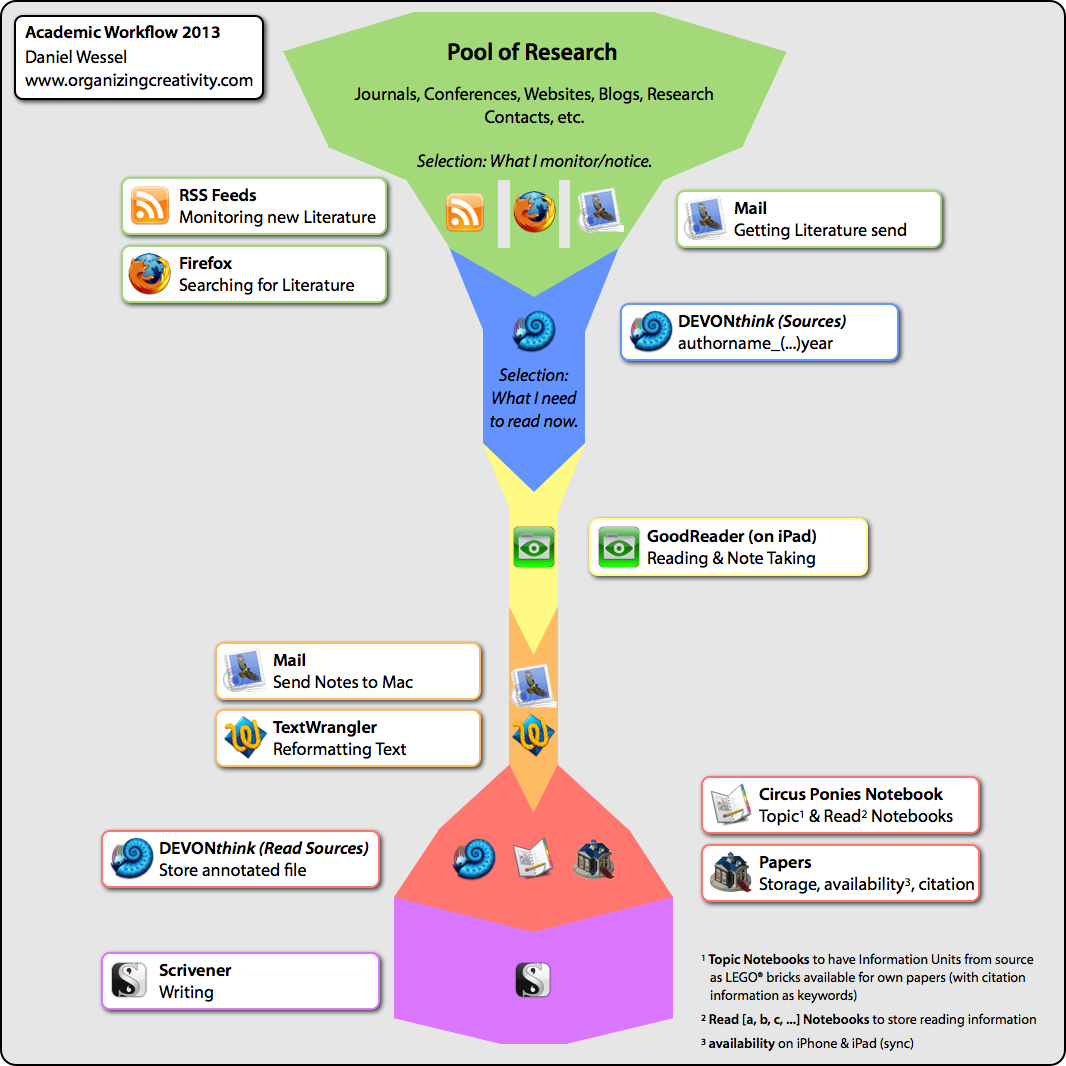
Short Description of the Workflow
There is a lot of research going on, in my discipline and in its sub-disciplines. I use RSS Feeds to monitor interesting journals and blogs. I also use Firefox to search for literature. Occasionally, I get interesting articles via Mail. I am selective here and save only material about topics I am interested in (which still leads to a lot of material).
All articles end up as OCR’d PDF in a DEVONthink database (called “Sources“) and every file is named in a default scheme (authorname_(authorname_…)year). That’s the bare minimum I do with the articles I get — I can do this quick and easy. DEVONthink informs me if I already have the file.
From these articles I select a few I want/need to read. I transfer the files to GoodReader on my iPad (via iTunes), read, highlight and annotate the file.
I use the “E-Mail File + Summary” function of GoodReader to export the highlighted text and annotations via Mail. On the Mac I use TextWrangler to format the notes a little.
The annotated PDF’s end up in a separate DEVONthink database (“Read Sources“), just to have them available for the future.
The notes end up in Circus Ponies Notebooks — the whole information is stored in a Read [X].nb (“Read A.nb”, “Read B.nb”, … depending on the first letter of the first author’s name) for safekeeping. More important are the Topic Notebooks where the information ends up for further use. Circus Ponies Notebook pages are outliners and each cell is tagged with the source information, making it easy to play with the information (use them as LEGO(R) bricks) yet always know where the information comes from.
I also use Papers for literature I have actually have read. This gives me a separate storage (in case anything happens with DEVONthink), allows me to sync all read articles with my iPhone and iPad (you never know when in a discussion with a colleague you want to show them something in an article), and to be able to easily cite the literature (Papers has a few nice features, more on this in another posting).
The actual writing is with Scrivener (brilliant writing program, although the typewriter scrolling sucks if you do not disable it in both views!), which works well in combination with Circus Ponies Notebook (both have their individual strengths and complement each other).
Concluding Remarks
As usual, organizing creativity is an individual process. This is how I work (at the moment) and it will certainly be subject to revision. It’s easy to replace part of the workflow with other components or ways, e.g., storing the literature in folders instead of DEVONthink, using Sente instead of Papers, etc. What I really like about this workflow is that it really flows. I can look around, grab literature like a squirrel (well, a digital squirrel), and then filter what I read and have (later) only the literature I actually have read in my literature manager. And of course, reading on an iPad is a blast, not only because you can make notes easily if you do it right.
Happy working. 🙂
Hi Daniel,
thank you for this great update on your academic workflow. I started using Circus Ponies Notebook for my data collection and idea structuring, and it works like a charm. But I had troubles implementing DevonThink into my workflow. I use a folder in Dropbox with all scientific articles as PDFs, with Title_Author_Year signature, which is very simple to maintain, easy to access on different computer systems (PC at work, Mac at home) and share (with students). For different projects I have a word file each, which I update with ideas and technical comments over time. But I am not sure if I should move them all into a DevonThink database for easier access.
Keep up the great work and thank you for sharing all your valuable information.
Cheers
Felix
As an overwhelmed Graphic Design student, I just wanted to say thank you because your blog is amazing and I’ve found it to be extremely insightful as well as motivating. Its hard to keep a handle on my workflow and not lose site of my personal creative process while trying to keep it separate from design projects I’m required to do in school. Growing up as an artist I constantly strived to “organize my creativity” and thought I was alone in my desire to systemize/try to streamline my creative workflow, now It’s actually something that is a reality and this poster is hanging by my desk! You have a real talent for providing a logical perspective on a topic that is usually seen as so abstract. So thats my “you’re awesome” rant.
Appreciate all your work, keep writing 🙂
Hoi Courtney,
cool, thank you very much for your comment 🙂
Besides the book I also recommend this poster here … it’s more complex but also more fun 🙂
All the best
Daniel
Hoi Felix,
thank you very much for the positive feedback 🙂 And yes, there are different ways to structure the workflow, DT is only one solution. Dropbox has an advantage when you want all your work always available (if the Internet is available). I think DT makes sense if you want to quickly collect articles (and especially the browser plugins for PDF export are really, really helpful to quickly capture for websites), find duplicates based on content (not file name). The disadvantage is that with one Dropbox folder, you are protected from giving different articles the same name (if you would only use authorname and year, where this can happen), DT would not warn here (which would be a problem later on). On the other hand, with DT you can use tagging. But like said, I don’t think that there is a “perfect” way to organize literature, it depends on your style and your demands.
Easiest way to find out would probably be to simply try it. Worst case *should* be some wasted money on DT, as you can export the files easily from DT. But if it works and you don’t see the need to change anything don’t do it — the old saying of “never touch a working system” holds true here.
All the best
Daniel
I have the free version of the book which I’ve thoroughly enjoyed and I still reference that poster all the time, its great. But, convinced my dad Organizing Creativity is a required textbook for my fall courses so will hopefully get my nice pretty color version soon 🙂
😉
(if only it were a required textbook — that’s every authors wet dream, as long as its not for one’s own course ;-))
Hi Daniel!
Congratulations for your book and the blog! It’s been really helpful.
I am trying to get a similar workflow up and running before I start with my thesis research and writing. Although I have been using Goodreader for my literature reading ( I agree that it is a great pdf reader,) I am thinking of introducing Sente instead of Goodreader in my workflow. Sente will provide me the same benefits as Goodreader plus the functionalities of a reference manager. I know that when you did your PhD work you didn’t use a reference manager, but I would like to know if you think that now it would make sense for a thesis workflow.
A further question would be if you know how exporting notes from Sente to CPN might work.
In any case, I have to confess that before I can start using Sente, I need to solve a fundamental weakness it has for me: it doesn’t include ISO 690:2010 bibliography format, which is the format I need to use for me thesis!! (I am already in touch with Sente Support team trying to solve that problem).
All the best,
Lucila
Hoi,
yup, I think it makes sense to use a reference manager — for the literature you have actually read (see this comment or this blog posting). I would not use it uncritically to add all the literature you find when you go on a binge. Go wild, but decide what you will read and only add the read literature (that you think you will use). This is why I store my literature in DEVONthink, read it with GoodReader (not with a reference manager), and then use a reference manager to have the reference available (and CPN to order the notes). I would separate sifting vs. reading & using.
Regarding export, I would look at the Sente site. They had an entry on exporting notes in an earlier version and I guess there are ways to do so in the current one as well. Not sure how the notes are stored. If they are stored in the PDF, you might be able to export them with Acrobat or Skim.
BTW, my workflow changed over time — it’s likely yours will as well. If you find something that is really helpful, I’d appreciate a comment 🙂
All the best
Daniel
Hi
Thank u very much for this tips in work flow. Im kind of person who loves using organising applications however; I couldn’t stick with one proper system to carry on and your post here will help a lot .
I have some questions for u please .
I usually use the iPad and I have paper 2 in both the iPad and my mac also I have the good reader on it. could u tell me why I should not use the paper for the notes and highlighting instead of using good reader then email and text wrangler to arrive for ur scrivener or notebook in the end ?!
another question is I couldn’t get the advantage from using both adevonthink and papers together ?!!? and notebook with scrivener in the same time ?! don’t u think using and stick with 1 application is more efficient ?
your answer will help in creating my work flow 🙂
Many thanks
kholoud
Hoi Kholoud,
there’s no “should not use” — only showing an option that might be useful for you or not. For me, I found out that I search literature like a squirrel on crack, so I have a lot of papers, but then I select which I read. It makes sense for me to store all the articles in one place and then select the ones I read and put them somewhere else. On my Mac, I store the articles I find in DEVONthink (easy, just drag and drop, no need to enter the meta-data). Then I select what I read. I use GoodReader on the iPad for reading, a) because I like working with it, and b) because it keeps the literature I am currently reading and the literature I have read separately. There’s another selection process, and differentiating between GoodReader and Papers helps this. Another advantage, in case something happens to the files in Papers, I still have the literature in DEVONthink (I’m using labels to indicate what is on the iPad and what is in Papers).
Regarding Notebook and Scrivener — have a look at this posting here.
All the best
Daniel