#Polymorphic Software, #TECH22
Technological advance is an inherently iterative process. One does not simply take sand from the beach and produce a Dataprobe. We use crude tools to fashion better tools, and then our better tools to fashion more precise tools, and so on. Each minor refinement is a step in the process, and all of the steps must be taken.
Chairman Sheng-ji Yang, “Looking God in the Eye”, in “Alpha Centauri”
I’m continuing to use DEVONthink (Pro Office version; see this posting for a very quick introduction of its strenghts). I am still transferring the information from my Wiki to DEVONthink, so this is a work in progress. While my main database is now at about 29 GB, it still works fine. Opening the database takes about a minute or so, but I only do this once every few days — the rest of the time it stays open — so that’s okay.
At the moment I think that it’s the best collection I have used so far — and it is very good to dealing with a lot of information/files you put into it.
According to the very helpful customer service (thank you :-)), the theoretical maximum number of documents is at about 200.000 and the maximum total number of words at about 300.000.000. So far, I’m at 50k of 200k files and at 1.2M of 3M words. So, there is still some room left. 😉 Coming with a very large collection (and it is a collection that I can import easily), I’m not concerned that I’m already at 25% of the amount of files, it would be akin to saying the apartment you just moved in was too small because with all your stuff from your old apartment there is only little space left. So, no sweat there.
So, how does my DEVONthink database look so far?
Note: I use the terms “groups” and “folders” interchangeably, because in DEVONthink any folder is actually a group, i.e., all documents in that folder are tagged with the group name and displayed in that group.
General Settings
The first thing I do with new software is to check the Preferences (application name in menu bar, then Preferences; or press cmd + ,). The global settings are powerful and often the default settings are not ideal for me, so they are well-worth a look. The downside is that in some applications they can screw up work, so think before you click.
Personally, I have chosen in General (don’t know the original settings): Alternating row colors in views, Display number of items inside groups, Highlight Internet links in views, Mark duplicates and replicants in color (duplicates are blue, replicants are red — very useful!), and colorize icons with label.
For Import I have selected Filename without extension as I do not want the see .txt or .rtf each and every time. The icon works fine to tell me which file type I have.
For Backup I have selected daily — note: it’s only the backup of the database information, not the files itself!
For Update I have selected on startup.
The right view
DEVONthink offers different views (View – [first six entries]). Personally, I think the “as Three Panes” works best (for me) — you get the group structure left, the content of each group top right and the content of the selected file bottom right.
It also gives you two arrow buttons which allow you to go through the content you had displayed previously.
![]() Very useful if you want to look up something (e.g., an image while writing something in an rtf file), have found it, and want to go back to the file, then simply click on the left arrow until your rtf file is displayed.
Very useful if you want to look up something (e.g., an image while writing something in an rtf file), have found it, and want to go back to the file, then simply click on the left arrow until your rtf file is displayed.
One References Database
I have put all my material that I still work with, PDF documents of articles, images, videos, etc. pp. into one database. Archived content of finished projects is in a Wiki. The reason for one database is that I think that different topics stimulate each other and if they are grouped (“put into folders”), there should be no conflicts. It also saves space, as some images, videos, documents, etc. are relevant for private projects and work projects. Disadvantage is that it gets large very quickly, but see above, it should work and for me (now) the advantages are greater than the disadvantages. If it gets too large it’s possible to split the database, although only some versions of DEVONthink support multiple databases.
Sort the material in DEVONthink
I strongly recommend sorting the material in DEVONthink. The reason is that DEVONthink is not a simple file/folder system, but offers some features that help you very much in sorting your data — most importantly recognizing duplicates (see below) and allowing files with the same name in one place (see below). I didn’t have problems importing a few thousand files in one go — simply drag them into the folder you want to have them. Even if it’s PDFs (and DEVONthink seems to analyze them to be able to suggest similar documents and to find duplicates) DEVONthink simply works — I noticed this when I accidentally dragged 8900 files, mostly PDFs, in one go into DEVONthink (cursed subfolders! ;-)). In comparison to other programs like Papers it doesn’t even heat up the processor — it just imports, one file after the other. So drag your collection into it (make sure you have enough space on your hard-disk left, it copies them!) and go drink a cup of coffee.
Files with the same name in one place
One of the stumbling blocks of current operating systems is that they do not allow you to have files with the same name in one directory. For good reasons, after all, how would you differentiate between the files? But there are ways and one of them is looking at the file size. If you try to clean up your collection with Mac OS Finder you get crazy when each time you move documents with the same name into one directory. It warns your that you are going to overwrite it and if you decide not to overwrite it, the files that are possible duplicates remain in the directory where you wanted to move the files from. Then you have to manually check whether the file is identical, e.g., by looking at the file sizes or the date-time information. This is very inconvenient. In DEVONthink you simply have the files in one group and can quickly check whether they are duplicates — or rather, let DEVONthink do the checking for you. If the files are the same, they are marked in blue (depending on the preferences). It doesn’t get quicker and easier than this.
Putting Images from Aperture into DEVONthink
I had a few thousand images in Aperture that I needed in DEVONthink. Be very careful how you put them in DEVONthink! Do not simply select them in Aperture and drag them in DEVONthink. I did this and somehow Aperture did not export the masters but a downscaled version of the images. While some images were still usable, comic strips (a few thousand Dilbert’s, Non-Sequitur’s, PhD Comic’s, etc.) were unusable afterwards. You have to export the Masters (or the Versions in Best Quality if you have made changes in Aperture and want to keep them) into a Finder directory and then import that directory.
If you want a downscaled version of photos you have taken yourself, because you do not want to use the photo in a presentation or print but only have it as a reminder of an idea, you can use the eMail export option. It’s optimized for small file sizes that work well on the computer display (but nowhere else). Either use the Export Version and select the preset for eMails or select the images, click on send per Mail and then — when the eMail is created in Mail, select all images there and drag them into DEVONthink. It’s quick and dirty and it works — for these kind of images.
Note: If you have accidentally imported images in two versions, the original size and the smaller size, and you want to remove the smaller size, sort them according to name, then have a look at the file sizes. The smaller one is either always the first or the second one with the same name. You can additionally right click on the header line of the view (where name, modified, etc. is displayed) and select “width x height” to get that information in the list view. Hmm, although thinking about it, making a smart group with type image and Date Added with the information when you have added the images should work like a charm … damn, that idea came to late for me.
Get rid of the duplicates
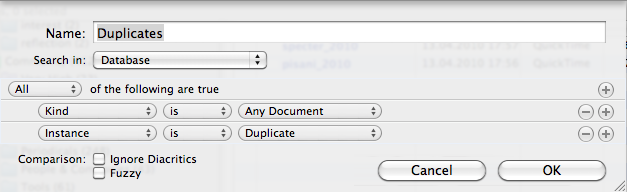
DEVONthink has the ability to recognize duplicates — by comparing the file content, not the name! This means you can put three images with the same content but different names and time information in DEVONthink and it will point out that these images are the same. This makes sense as files often have the same name but different content, e.g., two word documents representing different stages of the writing. It doesn’t go so far to recognize scaled versions of the images, but recognizing duplicates is a huge boon. The best way to deal with duplicates in the early stages is to go to the smart list “duplicates” (should exist, if not, make a smart group with “Search in: Database” (or where ever you expect duplicates) with the terms: “All of the following are true: Kind is Any Document and Instance is Duplicate”. You can also limit this to specific file types.
Next, if you have not already put files into a structure, you can select all duplicates in the smart group and use the script menu of the menu bar (looks like a scroll, the one belonging to DEVONthink on the left side, not the system one on the right), go to data, choose “Move Duplicates to Trash”. This leaves only one instance in the database*. The reason why you should do this only if you have not yet put the files into a folder structure is that I am not sure whether DEVONthink puts the ones in the Inbox into trash. In case you want to do this manually, sort the files by size (by clicking on the size header) or sort them by name. If you do not see such a window, use View and select the “as Three Panes” View.
![]()
So far the only problem I had with the identification of duplicates was with a two TED Talk videos which are regarded as the same although they are different, even having different file sizes — but they share the same beginning. I think I simply edit out the trailer at the beginning in one file — it should work.
* This is an example of how DEVONthink makes it hard for you to use its full power — judging by the name I had expected that it places all duplicates, i.e., all the files, into trash. In fact is leaves one instance. It should have been named “Move all duplicates except one instance to Trash” or “Move all duplicates save one to Trash”. Ideally there would be a “Move all duplicates in Inbox to trash” version, which would leave all sorted files intact but remove duplicates only from the Inbox. Selecting only duplicates in the Inbox would not work here because it should remove the one file in the Inbox that is also already in the database.
Find a good structure that works for you
I think you need a clear mental model of how you want to use DEVONthink — until you have that, you cannot use it effectively. There was a request for training in DEVONthink’s forum and while a single case isn’t reliable data (actually, only a datum), it’s usually a bad sign. But let’s be clear here: A bad sign regarding the communication of how to use it, the software itself is top.
Currently I have some input folders (or groups) and then a structure that makes sense to me, among others:
- current: Holds documents or replicants of documents I work with at the moment. I need to edit them quickly and I do not want to open folders/subfolders to get to them. One of the strengths of DEVONthink are the replicants. If you right-click on a file anywhere in your database and select “Replicate to” you can create a replicant (think file alias) anywhere else in the database. After that it doesn’t matter which file you edit, the changes will be in “both” files (it’s the same file that is displayed in different places). Very useful. Be careful not to duplicate it, because this will create a copy of the file and your changes will not be in the other file. If you have selected the color highlighting in the preferences, replicants are red (easy to remember via the “re”), duplicates are blue (mirror the “d” and you get the “b” for blue). The current group is the only folder/group that I have assigned a red label to, so I can find it quickly. If I want to go the the group where the ‘other’ file is, I go on the information inspector (Tools => Show Info; the i in the Task Bar or simply shift+cmd+i), at the bottom of the window is the Instances information, click on it and select the other file and you jump to that group.
- Projects: Contains groups/folders of my projects, ranging from publications to teaching to career to advisory, etc.
- Handbook: Contains a collection of files that all deal with doing my work as a scientist. Information on publication, APA standards, writing quality, some notes I made on how to improve what I get out of conferences, etc. Files from Sources, Images, or Videos are either replicated there or available via smart groups. For example, I have tagged a few of the very best TED Talks I have seen with “presentation” and “best_practice” and a Smart Group shows me these videos in “Presentations” as a reminder of what a good presentation can do.
- Topic Notes: My notes on the topics I work on (duh! ;-)). It includes a Glossary with smart groups that show the files with the explanations sorted in Grammar, Graph Theory, Statistics, Theories, etc. and normal groups for the main topics I work on (mobile media, reflection, etc.)
- Community: Contains files with Information about interesting Journals, People and Companies, Tools, Places, Conferences, etc. For example, the rtf files in Journals contain some information about the target audience of the journal, the topics, which issues I have read/scanned for interesting articles, etc. Each journal file is tagged with “journal” and a tag that indicates how relevant it is for me. Of the > 200 journals I have there, I can quickly check the journals with a relevance of “very high” by a click on the smart group.
- “Private Projects” and “Private Topic Notes”: Similar to the “Projects” and “Topic Notes”, only the information is private, i.e., definitely not work related. It essentially prevents (or I hope that it does) that I sit in a meeting and accidentally have photos I took at my last bondage shooting appearing on my screen. Like written in the beginning, I think that work and private interests stimulate each other (although not necessarily in the way of the current example), which is why I do not split them into different databases, but at times this can cause problems. Quite large ones if the notebook is connected to the projector in that moment …
- Sources: All my literature that is in PDFs. Given that I have transferred almost my whole library to PDFs via a very fast document scanner (and by gutting the books, yeah, I’ll end up in hell for that) and that nearly all my research literature is in PDFs, it is quite large (2981 files). So I have used the Data – New From Template – Registers – A-Z and created groups from A-Z and sorted them there. Each PDF also has a text or rtf file in the same group with some notes about the article (if I have read it). I’ll write more on the in a later posting, but it is crucial to have a clear structure here and it’s very, very easy for anything written: use the authorname_year style. If there is more than one author, use authorname1_authorname2_authorname3_[etc]_year up to seven author names (because this is the amount of names you have to write out in APA style, after that it’s first author and et al, so a paper with 8 authors would be firstauthor_et_al_year).
- WebCapture: Using DEVONthink’s Browser Plugins I can easy transfer a Website to PDF and have it appear in the Inbox. I put it into this group, tagged with the relevant information.
- Presentations and Lectures: Notes from, well, Presentations and Lectures, not sorted at the moment, but I’ll probably use subfolders/groups like year. Tagged of course.
- Images: Images are a difficult subject and I am still struggling how to organize the >40.000 images I have there. Yup, forty-thousand! In the best of all worlds, I would know the source of the image (e.g., the photographer or the artist/designer/painter) and would group them this way. But I didn’t get to that amount of images this way and the only way this worked is for comics, comic strips, and some artists I know very well. So I have tried to additionally sort them according to categories, e.g., Astronomy, ads, apps, design, Drawn Art, Jokes, and for most photos I used categories like Decisive Moment, Portraits, Street Photography, Landscapes, Cityscapes, Documentary, Animals, Plants, Underwater, etc. Problem is that they are not mutually exclusive, meaning that the same photo should be in different groups. Usually that’s what smart groups are for. So, at the moment I am using static (normal) group to make sense of the images I have and then create smart groups of the main categories (like Street Photography, Animals, etc.) and tag the photos — and this way I can give one image multiple tags to have it appear in more than one smart group. If I got time that is, 40.000 is daunting. Still, I think that keeping images in DEVONthink works better than keeping it in Aperture or iPhoto. Reason being is that I do not want to edit them or use them in a print project. I want to have images available for presentations, for stimulation (not only this kind of stimulation, thank you), inspiration, etc.
- Videos: Easier than images because I have fewer (about 100) videos at the moment, usually small clips. Tagged so that is it easily available where I need it.
Use the right view for sorting images
While the “as Three Panes” view is ideal for working with the collection, for sorting images I prefer to open the group into a new window (double click on the group) and select the “as Icons” view. You get a small display of the image and can easily select them and sort them into the groups they belong to. Use cmd to select multiple images in different locations or shift to select a group of images that are next to each other. Given that I am interested in portrait photos I had a large amount of these images and I used the following setup to quickly sort them:
Note: It was pointed out to me that the image here was NSFW, so I replaced it with a censored version. If you want to see the uncensored one, simply click on the image.
(Don’t expect much, I think the images are artistic, that’s why I saved them — as an inspiration, but tastes differ. However, I don’t want to get anyone in trouble with their IT department.)
In the middle is a open window (group) of the images I had to sort, on the left is an open window (group) of all portrait images, and on the right is an open window (group) of images that are not portrait photos. I selected the portrait photos in the group on the middle and dragged them left. From time to time I selected the images above the point I was and dragged them right. If you have only two categories (A and not-A), this works very well.
Use Smart Groups to have the information available where you need them
The killer feature of DEVONthink are the smart groups and the criteria they can be based upon. It’s like a smart list in iTunes or Finder, only it can contain anything depending on your criteria. You can base the contents of this group on: All, Content, Name, URL, Comment, Metadata, Author, From, Recipient, To, Title, Headline, Subject, Description, Keywords, Organization, Copyright, Album, Composer, Tag, Flag, Unread, Locking, Label, Width, Height, Duration, Size, Word Count, Kind, Instance, Item, Date Added, Date Created, Date Modified, Date Opened. You can use one or multiple criteria which either all have to be fulfilled or any of them. This allows you to get a list of all images with a width of less than 600 pixel who were added before date x as easily as getting all text files with the word “important”. Usually, I use smart groups based on tags, as I can easily specify files that I want to appear in a certain place.
For example, I use tags for the literature relevant to a course I am giving (tag: “sgl_kurs_2011”) so all the literature (pdfs) that is stored in the Sources Group in an A-Z index is available in the smart group SGL Literature (Searches Database with all of the following true: tag is sgl_kurs_2011). If I stumble upon an image or comic strip or video that is relevant for the course, I simply tag the file with “sgl_kurs_2011” and it appears in the smart group as well. Very, very convenient. Think about it, you do not need to copy the file or replicate it, it is just there — easily available where you need it.
Personally I would not use tags for categories that apply to all elements of a group. For example, I would not tag my 4263 Dilbert Comic Strips with “organization”, although they all deal with organization. It would make the tag on its own worthless, because whenever I use the tag I would have 4263 images in that smart group — not so smart anymore. Instead I remember that all Dilbert Comics deal with organization and use specific tags (e.g., teamwork) on the few very good Dilbert Comics where this applies to. Additionally, if I am working on a project (let’s say a course) and I find a comic that might apply to the course content, I tag the comic with that tag, e.g., sgl_kurs_2011.
Conclusion (so far)
In short, at the moment I am highly satisfied by DEVONthink’s ability to handle my data, to collect my files and to support me in my creative work. But I still think that DEVONthink has two disadvantages:
- It is not intuitive — it is very, very powerful and flexible, but it doesn’t show off what it can do for you. Which is a very strange disadvantage. If they would put up a few fully fledged case studies of people using DEVONthink (you can find some videos on their site and on YouTube but they don’t really cut it) it would help others to get a better impression of what you can do with DEVONthink.
- It is offered in different versions with different functionality. Personally, I think this is the Microsoft ex(?)-Windows still-Office way — and it’s a very bad way. It complicates things. With very few exceptions all Mac programs I know of offer only one version. It doesn’t ask you to pick and choose beforehand. It just gives you a program to work with, after all, it’s not like the additional functions would cramp up the application or fill up the hard-disk. Even Adobe, which I would regard as an untypical company regarding its Mac software, offers different packages but these packages contain different combinations of stand-alone software. There is no InDesign, InDesign Pro, and InDesign Pro Office, there is only InDesign and that’s a core strength of the company and those working with the software. Other examples are iPhoto and Aperture, which are very different and address different audiences. I cannot understand why they do not offer only one version and price them differently for students and teachers (educational license) and offices (business license). They still would get a fair price (based on what the person can pay for it) but would reduce complexity in purchasing, support and how-to’s. Hmm, perhaps a historical legacy embedded in the company, I don’t know, but it gives the impression that they themselves don’t know what should be included.
But still, these are disadvantages that other companies would dream of having. Currently my view of DEVONthink is like the Enterprise in “Star Trek XI” diving up from the gas clouds of Titan. It doesn’t look like there is much, but there’s something powerful — and it blows you away (yeah, and I’m a nerd ;-)).
 Scene from “Star Trek XI”
Scene from “Star Trek XI”
PS: I normally don’t write disclaimers but no, I’m not sponsored in any way by DEVONthink. And no copyright infringement is intended by the cuts from Star Trek XI, I hope it falls under fair use, it’s just an association I wanted to convey.
Other Postings regarding DEVONthink
- A very quick introduction to DEVONthink Recommended for getting an accurate mental model of what DEVONthink can do.
- DEVONthink Another good overview posting.
- Literature Management with DEVONthink Not only important if you are a scientist or student.
- From DokuWiki to DEVONthink If you have previously used DokuWiki, changing to DEVONthink is very easy.
I enjoyed the write-up.
However it would appear the screenshot used while describing sorting images could be considered NSFW.
I thought that would be worth mentioning.
Hoi,
thank’s for the comment — hmmm, you’re probably right, didn’t think about that. I’ve exchanged the image against a censored one but linked the original to the image. I think they are artistic, but hell, tastes differ (I think some texts and links here are more problematic ;-)).
All the best
Daniel
Regarding duplicates; the current ‘remove duplicates’ is correct as that is what it does. If there are two files the same only one of them is a duplicate as the other is the original. The command removes that duplicate and leaves the original.
I suppose it’s a case of semantics but that’s how I see it.
Interesting article though.
Cheers
I think that having versions at varying prices is fine in the case of DEVONthink. Users only need to pay for the features that they use. A person can upgrade when they find that they require additional features, such as the ability to create multiple databases, which is only available in DEVONthink Pro and Pro Office.
Educational discounts only benefit a relatively small group of people. An independent researcher like myself with no direct educational institutional affiliation would be forced to pay full price for features that I don’t need at this time.
In my case I started with DEVONthink Personal and it served me well for several years. But after I began to use the program more, I saw the value in having multiple databases, so I upgraded to DEVONthink Pro.
And while I recently purchased a ScanSnap document scanner, I don’t really see the need to be able to scan documents directly into DEVONthink, since I rarely put scanned documents into a database. The OCR software bundled with the scanner is the same product that is integrated with Pro Office, so I am not missing any vital OCR features. I saved myself a nice piece of change by not upgrading to Pro Office. If at some point I need to scan a lot of documents directly into DEVONthink I will upgrade to Pro Office.
Hoi,
thank you for the comment — one question: Which file is which? If I import a bunch of files and two of them are the same, both are marked in blue, but which of the two files is the “original” and which is the “duplicate”? Is the one that was imported first the original?
All the best
Daniel
Hoi,
thank you for the comment — I can see your point, but I still think that multiple licenses have more disadvantages than advantages. Perhaps it’s personal preference, but I usually test out a lot of features in a program to see whether they are useful for my work, and having to use a “castrated” program that lacks features would feel … not right. I see the need for different versions if physical parts are involved (e.g., computers, cars, etc. which actually cost money to produce (and not only to develop)), but with software, there is no need for this. Regarding the educational license, sure, if you are not a student or part of faculty you would not necessarily profit from an educational license. Perhaps there could be a license model which would include independent researchers or there are other ways. For example, to get my student license of Adobe Creative Design Suite I took a class at an adult education center (worst three days of my life) to qualify for an educational license.
But like written, I can see the point but I think there are better solutions which save users money and allow them to use the tools to the fullest. I hope that these licensing schemes will fade out in the future and that there will be only one license for all, albeit at different prices.
All the best
Daniel
@Daniel
This is an important question because sometimes you need to see and retain when you first downloaded something. I wish I had the answer to that question about retaining the original.
So, I’m a television writer who’s interested in giving DEVONthink a try…I was intrigued by Buckell’s and Johnson’s essays on using it to help with their books.
However, I’m a pretty hardcore windows user. I do have a mac, but I’m hard-pressed to imagine making it my primary desktop (or making any Mac I might buy my primary desktop).
Given that, I’m trying to figure out if I can use something like Synergy (which essentially lets me use the same keyboard/mouse on my mac and windows-machine by just mousing across / between the monitors) and running DEVONthink on the Mac… basically turning one of my monitors into a dedicated DEVONthink window.
My question is about the tools available to me for sending data to DEVONthink. Are there ways to send stuff “remotely” so that I can use my windows-machine for browsing and still send things to my database?
I’m kind of hoping that maybe people who use DEVONthink on their primary machine (that is a mac) but are forced to use a windows machine (say, at work) might have created a need for these kinds of things…
…but basically, can i add to a DEVONthink database from a remote windows computer?
Hoi Scott,
hmmm, first of all, thank you for the literature tips — searching for the essays I stumbled upon the DEVONthink page for writers — haven’t read it yet but it looks interesting (although I wouldn’t do everything with DEVONthink, I’m always open to doing the things I do with DEVONthink better 😉
Synergy looks interesting too, although I am very skeptical in using two different computer systems at the same time. You need both and over time, I guess the additional effort will impede your motivation to do so. I’m not sure whether there is an equivalent of DEVONthink for Windows, so I guess you’d have to switch to Mac if you want to use it. As you can install bootcamp and as there are ways to use Windows programs in a dedicated window, this shouldn’t be that much of a problem — unless your employer ‘forces’ you to use Windows at work. Personally, I use my private MacBook Pro at work — it’s an extension of myself (I have configured it to work perfectly with my style of work) and as I work in Academia, there is no problem from my employers side of view. It also prevents me from having to carry two notebooks wherever I go and I can use material on my private computer for my work and vice versa (e.g., images for presentations, etc.). Not to mention having music to listen to at work, or other material if I want to show someone something. So, my guess would be that it would be beneficial to try out DEVONthink, whether it works for you or not, and if it does, use it (and a Mac) and the main computer. But whereas splitting things up didn’t work for me it doesn’t mean that it does not work for you either and when you have tried it out I’d be interested in an update.
All the best
Daniel
@Daniel
thanks for the reply..
well, i don’t know how devonthink is going to work for me but synergy is great… i have a 4 monitor setup on my PC anyway and the truth is that I only really make use of 3 of the monitors…
…so what I’ve done is basically turned one of the monitors into an external monitor for my macbook… synergy makes it so that when i mouse over to that window, the experience is seamless to me… i’m now pointing and clicking on my mac… it also is able to copy the clipboard between the two systems so i can highlight and copy in firefox on my windows machine and then mouse over to my mac window and paste that into my devonthink inbox…
…the difference for me is that i don’t really use my macbook much anyway… i have an asus tablet running windows 7 and onenote that is my laptop… and an ipad… those two things make it so that my macbook basically gathers dust… so while this is an expensive solution in that it has basically grounded by macbook, it’s pretty cool… and i’m lucky that i don’t have really have a need to move the macbook around…!
and now i can use scrivener too! (well they have a windows version now but it doesn’t all the feature i want)
@Daniel: thank you for the great blog. I keep on reading and re-reading your blog. It is so helpful. I just want to point out for you that a website called screecastonline, it is behind a paywall unfortunately, recently released a good cast about Devonthink that really helped me to understand the software.
@Scott: I think OneNote is an amazing application. If you don’t have any other reason to shift to mac, I think it is wise to stick with it. Devonthink specifically so poor at note taking. I specially missed the tagging power of OneNote, where I put my tags at the edge of the paragraphs to remember an important point, phrase or quote. Onenote has a note-based organization. you write your notes, collect the materials relevant to the notes into it, drop pdfs, read them, jot down the points of the article on the pdf itself (thanks for the amazing OCR Onenote comes with), develop your own ideas around it… so good for writing projects. You can not outline inside the Devonthink; you can not tag a paragraph or a quote. Devonthink is great for collecting information at grand level, I also like the idea of replicates and groups, the artificial intelligence… but it is so poor for writing (outlining, drafting).
I’m curious about your gutting of books. I’m frustrated by having a mix of physical and digital books, mostly because of no search capacity in the physical ones. I take it you cut them up and then scanned to and OCR’d PDF. Gives search plus original page numbers,which conversion to ePub would lose (nor would you ever get the conversion time back). Any tips for pulling the books apart that you can share?
Hoi David,
I already did in two blog entries here:
I also recommend “Organizing Creativity” on page 319 (book numbering, Acrobat page 160, Digitizing Information).
All the best
Daniel
Thanks Daniel. Sitting in a coffee shop waiting for someone who is late. The perfect time to check those links out.
Hi, thanks for the great writeup! One thing that is not apparent to me as I investigate more about DEVONthink is whether the power of the associative AI relies more on the tags of your files or the content.
For example, if you have two documents that contain text that pertains to similar topics (yet not the exact same language), would the AI associate the two files even if you leave them untagged or would you need to tag them for it to associate them? Thanks!
You do not need to tag the files — DT looks at the content and tries to match the documents this way. Can’t say how well it work, given that I do not use this feature.
Thanks for this great write-up. As you point out, there’s a distinct lack of detailed usage scenarios written up for Devonthink. Reading your article clarified much.
Jonathan
P.S. When I came across the censored pictures, I figured they were of your aforementioned bondage sessions! 🙂 Disappointed. Nothing but artistic beauty. Oh well. lol
Hoi Jonathan,
ah, well, nope, just some photos from deviantART which serve as inspiration 🙂
All the best
Daniel
Daniel,
Many Thanks for the write-up.
I know it’s a few years old now, but for someone like me, just starting to play around with DEVONthink, it’s a fascinating view of how someone else is/was doing things.
When it comes to images, did you consider importing links only, rather than the files themselves?
I have a bunch of about 700 images which I use mainly as prompts for fiction writing. I may be missing something (like I say, very much a DEVONthink noob) but it feels as though I don’t need the files themselves in my database, I just want to be able to browse them from with DEVONthink. Although with links, if I did want to edit them in say, Photoshop, I can still do that from with DT.)
Thanks again for sharing.
Hoi Sam,
good question. There are some arguments for and against using links instead of importing the actual files into, e.g., DEVONthink. You get this option with a couple of other programs as well, e.g., Circus Ponies Notebook or Desktop Publishing Software like InDesign. You could, for example, import the links in different programs and then change the original to have them changed in all places. Haven’t tried it and there might be unintended consequences with some programs. After all, image attributes like size might change. But it’s one of the reasons why you usually have to manually import images into an InDesign file — linking is the default which makes sense if one person is working on the text and the other person goes over the images.
However, for using DT I would recommend importing the images. Even 700 images shouldn’t take up that much space and you can then backup the database and know that you have all the images saved as well. You can still easily edit them with an external program (right-click and then “Open with …”). I have put all my images into different DEVONthink databases (e.g., Argumentative, Comic Strips, Photography, Paintings and Drawings, …). The only exception is photos I have taken myself. These I usually edit in Aperture (RAW files) and then export. Still, even those edited pictures end up in a DEVONthink database (as jpgs, if just as reminders scaled down). I think it’s just great for reference material.
BTW, there are a couple of things you can with images in a DT database, e.g., use tags to indicate which images you have already used, use replicants or smart groups (e.g., based on tags) to sort them, etc. pp.
Hope these thoughts help. In short, I’d import them. You can always export them (just drag them or the group they’re in outside of DT onto the Finder) and DEVONthink should leave the images itself in peace (in comparison with image programs that automatically ‘enhance’ imported images).
Nice reading about an actual use case of DT, about how you use it.
The more I use DT products, the more I see its awesome capabilities.
Yet, the one frustration I have still is that I must choose ONE place to file each thing. Dupes and Replicants are helpful, but I still go back to The Brain because you are expected to link things together, web-like. Now, if I can get The Brain and DT to work together up effectively…..
Joseph
Hmm, I think it’s actually pretty useful to have each thing in one place. Sure, I’ve got ideas for a total management infrastructure like piece of software, but I doubt it would actually work. It would be one behemoth and much to slow and inflexible. But it’s a question of what you want to be taken over by the digital world. For me, I like to connect things — have DT for the source material, sort notes for projects in CPN, then use specific software to implement them (e.g., Scrivener for writing or InDesign for layout). But everyone has his/her bottlenecks and weak spots where software support is helpful.
BTW, didn’t know “The Brain”, looks interesting, but I’m a bit weary of mind maps (take up large screen real estate). Also looks like a lot of writing is involved to create them. Personally, I love mind maps for learning about a topic. But for storing information … don’t know, seems counter-productive to me. But if it works for you, how do you use it? For how long? Which information do you store? What are the strong sides of it, and what are the weaknesses?