If you have eight hours to cut down a tree, it is best to spend six hours sharpening your axe and then two hours cutting down the tree.
Anonymous, on the benefits of having good tools
I love GoodReader, an App for the iPhone and iPad. It allows me to read my literature digitally and easily highlight passages I want to use later and add notes.
However, when I export the highlighted text and notes via the “E-Mail Summary” function:
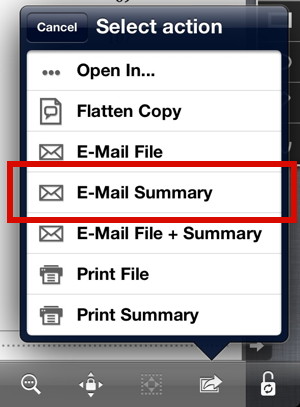
GoodReader adds information that is not that useful for me:
Highlight (yellow), 14.01.2013 18:14, Daniel Wessel:
a focus on both the scholar and the text or what they call text work/identity work
While the highlight information (which color, when, by whom) might be useful in some settings, it’s information I don’t need when I deal with the text in Circus Ponies Notebook. A clean text file with only the information itself followed by line breaks would be more handy.
A simple search and replace cannot be done, as the date/time information changes. But there are ways to deal with this variable information. I highly recommend copy & pasting the summary into a TextWrangler file (TextWrangler is free and very powerful text editor for Mac OS) and use the grep function to search and replace.
You have to check grep (and uncheck it later, because it is a very different kind of search) in the Find Dialogue:
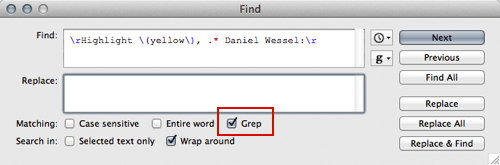
If you search for:
\rHighlight .* Daniel Wessel:\r
(use your own name, and activate “Wrap around” to find every occurrence no matter where you are in the file) grep will find all lines which start with a line break, followed by “Highlight” and end with your name and a line break. If you leave the replace field blank and select “replace all”, it will remove this information.
If you want to keep the information which color you used, you can replace each color with another piece of information. For example, searching for:
\rHighlight \(green\), .* Daniel Wessel:\r
and replacing it with
INQUOTE:
will replace all green highlight lines with the text: “INQUOTE: “. Given that I use green highlighting for sources the text I am reading quotes, this is crucial information to maintain (I would not want to imply that the authors did say something that the sources they cite actually have said).
So, when I deal with this text fragments, I first use:
\rHighlight \(yellow\), .* Daniel Wessel:\r
and replace it with nothing to get the normal text highlights as a single line each, and then:
\rHighlight \(green\), .* Daniel Wessel:\r
replaced with:
INQUOTE:
to deal with the texts the authors cited.
Notes (e.g., “Note (yellow), 14.01.2013 18:14, Daniel Wessel:”) and page numbers (physical counting) remain in the text, allowing me to quickly find the page if the meaning of the text fragment is lost.
A note about Grep and Regular Expressions
BTW, if you are interested in how grep works — all that I can tell you is that .* equals any character no matter how often and that you need a \ to make sure that a ( or ) is seen as character and not as part of a grep command. The \r equals a line break.
However, there is a lot of information out there about grep and regular expressions which can make a huge difference in dealing with text, esp. logfiles or any other data with variable or fixed parts. Before you spend ages doing it manually I highly recommend reading about it or asking someone who is an expert in it. But be careful — grep/regular expressions are very powerful and you can quickly destroy your text (or more) and a small mistake can have equally huge consequences as the benefits it might provide!
Thanks for this tip! I find the summary feature very useful, but it always feels like a chore to use it. I hope the developer can make some improvements to this area. Interestingly, my date format is different than yours. I suspect it uses the system default for date format. Thanks for the post!
Could be dependent on the system settings, but it’s easily adaptable. Grep is very powerful but not especially user friendly (would be nice if you could simply select parts of the text and designate the fixed and flexible parts of the text, but well … and yes, there are a lot of improvements possible … would love to get some integrated reading-collecting-solution.