They must often change, who would be constant in happiness or wisdom.
Confucius
One of the great risks when you start to deliberately attempt to improve your workflow is that doing so becomes a goal in itself. It’s fun, improving one’s workflow. Using more and more features for ever more intricate purposes, before switching to another solution altogether, because some “tiny but crucial function” was not possible in the old workflow.
I really think there is something of a valley of “almost-perfect-absolute-discontent” in work flows. You have a work flow that is almost perfect. And if you get really close to perfection the discontent with this almost perfect solution skyrockets. Because it is so close. It can really take the drive out of any creative endeavor.
So, I think it’s best to have something rugged, something that works good enough — and screw perfection. Times change and nothing is perfect forever, so why invest almost unlimited amounts of work to get to a very time-limited almost perfect solution?
Personally, I know that there are things I could optimize in my workflow, but in doing so, I would have to concentrate all my time and energy on optimizing that workflow, and not on doing any work. So good enough is actually enough. And I’m happy to report that my workflow is more or less stable over time. Meaning I’m on to something that works for me long-term. Yeah me 🙂
Currently, that’s my workflow:
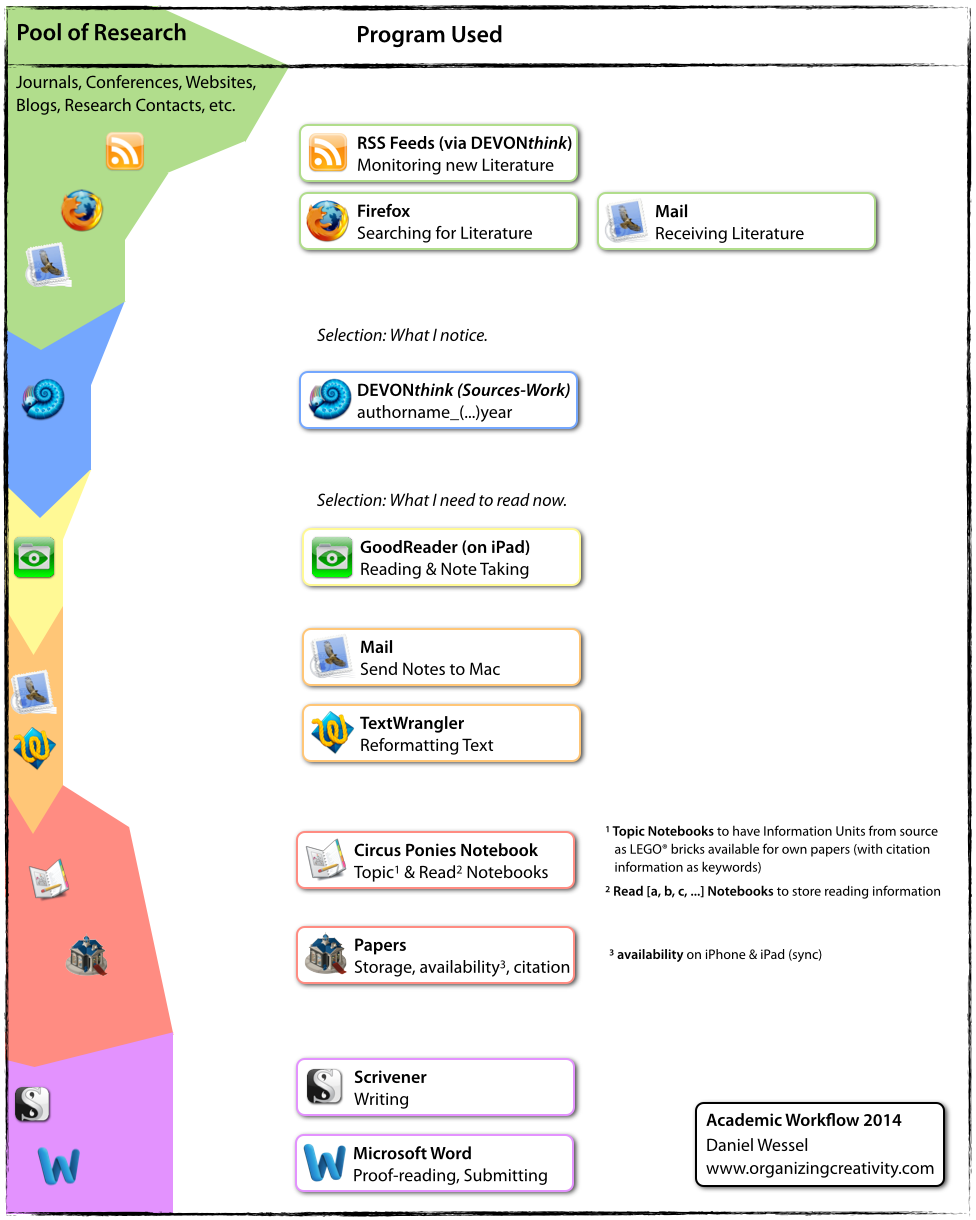
There are a few minor differences to the workflow depicted here over a year ago. But hardly anything of importance. But still, let’s go through the workflow in detail here:
- Staying informed on current research (green)
I use RSS feeds offered by many journals to stay informed about the articles they publish. Published articles are at least 6 months to (a) year(s) old, but still, better than nothing. I also use it to subscribe to blogs or interesting YouTube channels. Interesting things do happen outside of peer-reviewed journals as well.
I also use Firefox to actively search for literature (and to download the articles from the RSS feeds).
Also, some articles do come in via eMail. It’s nice to have colleagues — inside and (mostly) outside the organization you currently work for who provide you with interesting articles. - Collecting “interesting” articles (blue)
Actually, not only articles. Anything interesting I encounter ends up in DEVONthink. There’s a database for articles, one for websites (using a handy “get me this website as PDF in one click” browser plugin), and even one for private sources (if you get to a workflow that really works, suddenly even your private stuff ends up caught in it ;-)). But still, interesting is one thing, actually reading and working with the content another. So, anything I encounter that I find interesting ends up in DEVONthink. No matter whether I read it and work with it, at the very least it gets saved in an author_year filename. Meaning I can quickly find out whether I already have this article. And I can use this naming scheme to quickly reference to an article — which becomes important later on. And in case someone writes multiple articles a year, or people sharing the same name, _a, _b, _c gets used. Thing is, DEVONthink is my “catch all” box for the interesting articles I notice. - Reading Articles (yellow)
I am a big fan of reading digitally. Okay, you don’t get the nice smell of good books, but let’s face it, most articles smell like ozone anyway. And used books more often than not smell like cigarette. Cold cigarette smoke. But reading digitally got it’s advantages. You can quickly highlight interesting passages and get the highlighted text exported for later use. E.g., in topic notebooks. I use my iPad (3, I think) and GoodReader to read articles and highlight interesting passages. I also make notes to ensure that I get the gist of the article. It’s embarrassing to cite author x for proposition y when in fact, this person just mentioned something for y but is actually for z. Using the “E-Mail summary” feature all the highlighted text and the notes get exported via eMail. Really convenient. - Reformatting the notes (orange)
Even when the notes and highlighted text arrive via eMail, some reformatting is often needed. Luckily, TextWrangler is really helpful in this regard. Have a look at this posting. You get tidied up notes of the text you have read. - Read and Topic Notebooks — and Papers 2 to actually use the literature (red)
The redundancy here might seem strange, but there’s method in it. I copy and paste the highlighted text into Read notebooks (using Circus Ponies Notebook) as well as topic notebooks. I got notebooks on general work related issues, data analysis, and some regarding my research topics (e.g., mobile media/persuasives, or critical thinking/reflection). Really useful.
Also, I put each paper I have actually read into Papers (2, because the software is buggy and puts style over stability — version 2 works … well enough). With the sync feature I have all papers I refer to available on my iPhone and iPad. It also allows me to use the cite-while-you-write feature to quickly refer to the literature I have read when I write a paper. I cannot stress this issue enough. Do not put all the literature you stumble upon in your reference manager. It will make it so much more difficult to refer to the literature you have actually read when you write a paper. Reserve the literature manger — no matter which program you use — for the articles you have actually read (and are willing to cite). - Scrivener and Microsoft Word (gasp!) for writing
Okay, this is my dirty little secret. Or rather, my rotten little secret. Dirty sounds way to appealing. But while Scrivener is simply the best program I have encountered so far for writing, too few people use it. The people who do use it get more every day (recently converted someone — yeah!), but still, when you have to work with a proof reader or submit a paper, frequently you do need to use Word. So I write the text in Scrivener, often I need to compile it to Word to allow others to read it. But anyway, Papers (2) cite-while-you-write feature is really useful, especially when you put your content outline in Circus Ponies with the sources as keywords next to Scrivener (see the last image in this posting).
And that’s pretty much it. A relatively stable workflow to deal with the incredible productivity and information in science, and to — relatively easily contribute to science. Although this is my solution — and even the best workflow cannot compensate … let’s say rather unfortunate environmental factors … it’s something I am relatively proud of. I went into science (or rather: Academia) blind. Without knowing how to deal with the work — and I found a working solution. Perhaps it is helpful for you too.
Whether it is or not — in any case, I wish you good luck.
Hi Daniel.
Did you ever considered switching Word for Nisus Writer Pro? (I’m in that process now).
Is Mac OS native, uses an universal format – rtf – and integrates smoothly with Scrivener (the Literature and Latte people swears by it), and can also go back and forth with Word (I tested it) if it is needed for collaboration purposes (has compatible comments and track changes). And, of course, is much much less cluttered (or none at all) than word and more visual appealing. Just a suggestion…
Hoi Luísa,
thank you for the recommendation — had not heard of Nisus Writer Pro yet. Looks a bit like Pages, but may be an alternative to Word. Although in cooperative work that involves bouncing the document around again and again and having it opened and edited on multiple computers with different OSs, I’m a bit skeptical of using third party software (we had some bad experiences in a project where even using different Word versions caused file corruption). But still, looks very interesting and I’ll try it out. Thank you 🙂
Interesting article thanks.
re: “I cannot stress this issue enough. Do not put all the literature you stumble upon in your reference manager. It will make it so much more difficult to refer to the literature you have actually read when you write a paper. Reserve the literature manger — no matter which program you use — for the articles you have actually read (and are willing to cite).”
Do you think this is a work around the limitations of the existing tools to filter read items and cite-worthy items or is it a psychologically useful process to separate?
cheers
Good question, a bit of both, probably. I think reference managers make it hard to differentiate between a) did read and will use literature and b) got in via a wide search. You can make separate lists or use tags, but it usually still clogs up the database. And it’s hard to exclude them if you use it for citation.
But then, there’s also a psychological aspect. Seeing thousands of entries (e.g., number displayed while syncing) and knowing you have read only a small part — I find it discouraging. Especially when you do not have the complete citation information. You will probably likely see entries with, e.g., missing author, title, journal, or whatever. It’s just an affordance of displaying the entries in a table.
So I strongly recommend searching wide, keeping the literature (as author_year.pdf) in one place, but then screening the literature and being selective what you include. I do not have that many entries in my reference manager (only several hundred), but I know I have read all of them.
BTW, another issue is backups and sync to mobile devices. My work literature DEVONthink database has nearly 8000 PDFs. I have a “mobile sync” list with a selection of texts I carry with me — otherwise it would not fit on my mobile device. But my Papers 2 database is synced with my iPhone and my iPad, because it’s only a couple of hundred texts. Sure, you could do something similar by setting up sharing lists or the like, but … I don’t know, just feels better to keep the inbox separate from what I have really read.
Hi Daniel,
I find it very convenient to have my notes on my iPhone, but so far I have not been able to find software that would help me do this. I love Journler, but it is sadly shut down, and I am not that computer savvy to know how to migrate all my notes into Devonthink. That said, I have a couple of questions for you:
1. Why don’t you use Devonthink as your Circus Ponies Notebook? What limitations do you see to DevonThink? Do you find the iPhone app for Devonthink useful? That would be the primary reason why I would select Devonthink.
2. If you had to create a Kanban chart for your workflow, how would it look? What would be your WIP limit? And would you use all of the stages you described above or adjust some of them?
3. I am subscribed to a number of journals and listservs in my field and receive emails regularly, but I have problems accessing the information on my phone. The journals might provide only the titles and I have to log into the school system to read the article. That means that I have find the long library number which is stored in 1Password, but cannot be conveniently retrieved from my browser on my phone, so reading on my phone becomes so cumbersome. If you had a way to resolve it, would might it be?
Thanks! Very informative blog!
Hoi Anya,
1. DEVONthink is great to store files, whether it’s images or pdfs or anything else. But you can’t really work with the content. It does not has an outliner (but it can handle, e.g., OmniOutliner files). Re phone app — not really. Use it only infrequently. For pdf transfer I rather put them into GoodReader directly. Works via USB, much faster and safer. If you just want your files with you and don’t really need sync, GoodReader might be enough. When (if) DEVONthink manages to get DEVONthink2Go2 running, then DEVONthink might be useful again here.
2. Good question, if I find the time I might create a new flowchart. At the moment I’m swamped though.
3. Hmm, is there a way to get the notifications differently, e.g., using ScienceDirect’s RSS feeds? Then install an RSS reader on your phone? Hard to recommend anything without knowing your current process, but perhaps step back a bit and look at where the information comes from and whether there are different ways to get the information — then in a more convenient format. Also question when you want to have the information and whether you can, e.g., download the info on your computer and then sync the info to your phone.
Best regards
Daniel
HI Daniel,
Thank you for your answers. Luckily, DTTG 2 is running and it seems to be a smooth ride. So far 🙂
If you can share how you use OmniOutliner to make sense of the collection of notes and quotations you have gathered, I will appreciate it.
My question about kanban was about how you manage all deadlines. You have a central project on which you work, 7 others for which you gather information and many more in which you are interested. That alone can take 40 hours per week. On top of that, however, you have teaching obligations (if I am not mistaken), and I am sure that’s not all. How much time do you dedicate for the core project per week and on the other 7 projects? How much time do you aim to spend on reviewing the latest literature in your field and how much do you actually spend? And how do you juggle deadlines that seem to crop up out of no where and are always way too soon (e.g. grant applications, etc.).
Thanks for your time! I have greatly enjoyed your blog.
Hoi Anya,
still a bit swamped at the moment and still not quite … satisfied with the OO solution. I am thinking of adding a top layer but it’s not tested out enough to write about it. Will write about it when I find a solution I think is worth sharing.
Great to hear that DTTG2 is working out for you. Took em long enough 😉
Best regards
Daniel
Hi Daniel,
I keep coming back to your website for ideas on how to build up a good workflow. (I am at the very beginning of my PhD and figured it probably makes sense to invest in that.) Since this post is a bit older I wanted to ask you a couple of questions:
1) Are you still using papers? Or is it bookends now? I haven’t really found a reference manager that works for me, but I am not sure if that’s me or the reference manager.
2) I was also wondering why you are using the reference manager so far down in your workflow.. Don’t you loose track of all the ‘potentially interesting literature’ in DT?
3) Finally I would second Anya’s request in case you have any updates on how you use OO as a replacement of CPN. CPN seems much more intuitive somehow.. To bad it’s gone. I’ve tried OO but I just can’t really get my head around how to use it efficiently.
Thank you! I’m glad I found your blog 🙂
Best wishes,
Katrin
Hoi Katrin,
hmm, let’s see:
1) I switched to a list of the references I have already used and a bibtex file. Problem was that papers were mostly written with others, so using a reference manager did not really work out. Collaborative work was challenging enough (I *hate* Word, but that’s usually the lowest common denominator, in more ways than one). In the end, it was just easier to copy-paste the reference in.
2) Not really, I use tags for current projects and labels to mark which articles I have already read. Useful parts end up in topic outlines anyway. I never got used to using reference manager for managing anything else but references. Don’t like the notes and tagging options. Find it easier to use DT for that.
3) Yep, CPN’s death blows. OmniOutlines are okay’ish, but they are not CPN. They get slow if they are over 2k to 4k rows, I get the feeling like OmniOutliner got a couple of memory leaks (used working memory sometimes approaches 1 GB). And yeah, I really miss CPN. But I make do with OmniOutliner, even despite being not so good. It works well for storing information, the search function is quick and nice (using cmd + f goes through the hits one by one, using the search fields shows all hits at once), the iOS version is fast (enough) on a current gen iPad. But yeah, it’s not CPN. As for the use for yourself, it’s always the task that determines the tools, so, question is, what do you want to do? CPN works almost as good as CPN for creating content outlines and the like and I would still highly recommend it for this purpose.
Hi Daniel
Thanks for your reply.
Actually after writing my question and thinking a bit about reference managing/ where to include it, I realised that for me it’s probably better to include it later. Since I’m using DT to tag stuff, I don’t really need to do that in the reference manager later, and I prefer keeping my notes in an OO file.
I’m using OO basically for content outlines, but I just haven’t quite figured out how to do that. I feel like things get clustered and messy very quickly, but it might have to do with not having quite figured out how to write content outlines. I don’t think I can push an outline as far as you describe it for your thesis (basically being able to write only looking at the outline). I guess it takes some practice and patience building the outline.. 😉
Topic outlines scare me a little, because I never know how to make sure that I put the information under the right topic.. not sure if that makes sense.. I guess it’s a similar issue with tagging, but there I just tag everything I think is related.
I also watched your youtube video on how to write an academic paper which helped 😀 thanks for putting all this information up, really appreciate it.
best,katrin
Hoi Katrin,
hmmm, in general, you have to find what works for you — well enough, not perfect (otherwise you’ll optimize forever without producing anything). Regarding the content outlines — yep, I see the issue of not knowing where to put what. Especially considering the structure might change over time. However, hierarchical ordering can help here, as well as expanding a few levels and checking to top structure elements. Esp. for dissertations and articles, the overall structure is clear (usually IMRAD in empirical sciences). Then you can go by main points or other structuring elements (e.g., in introduction: what is it about? why should I care? what is the state of the art? etc., depending on how the document is usually structured). And with outlines, you can easily move whole parts (with all the child cells) into different parts of the document if so needed. OO’s search function is also nice (not cmd + f, but using the search window to have all results displayed on the left). Personally I’d recommend going through your outline occasionally and have a look what you have and where you have it. The structure might change repeatedly, but at least no information will be lost and you can move it easily. Just make backups frequently (on another drive) and if the size (or amount of cells) becomes a problem, you might split up the outline into different files (e.g., introduction, methods, …). CPN was much for forgiving when it comes to very long outlines than OO.