“Imagine a banana. Or anything curved. Actually, don’t, cause it’s not curved or like a banana. Forget the banana!”
The Doctor, describing conceptual space, in “Doctor Who: Space and Time”
I’ve repeatedly written posts about the joy to read books digitally and how to quickly scan paper books. Given that I spend the last weekend at home and took care of the last books I had stored in my old room, I’d like to give a short update.
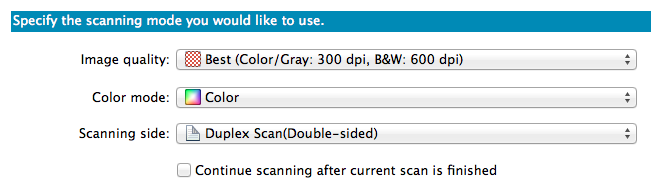
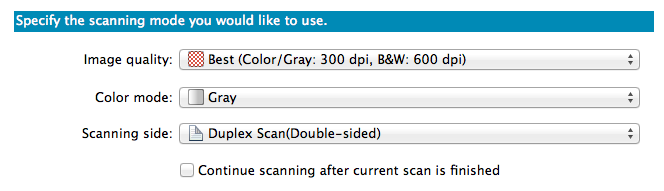
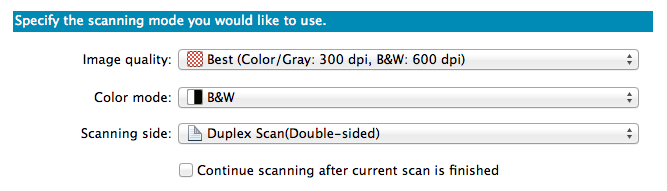
The books I scanned varied in size, color vs. b/w, amount of pages, etc. When I scan the books, I usually scan color books in color and with the best quality. In rare cases, I use gray (if it is really a b/w book with a lot of pictures), and for most paperbacks/novels I use b/w (except for the cover).
These are the settings for my ScanSnap S1500M
Color

Gray
B/W
(no compression setting)
However, what makes the scans worthwhile happens after the scan.
Using Acrobat (still have Adobe Acrobat 9 Pro) I first use Reduce File Size (with retain existing, but saved as new file) and then OCR.
Saving the documents as new files lets you easily keep the original scans in best quality — in case you ever need them. The effect of reducing the file size is incredible, just look at the original sizes, after reduced file size, and after OCR (OCR adds a little).
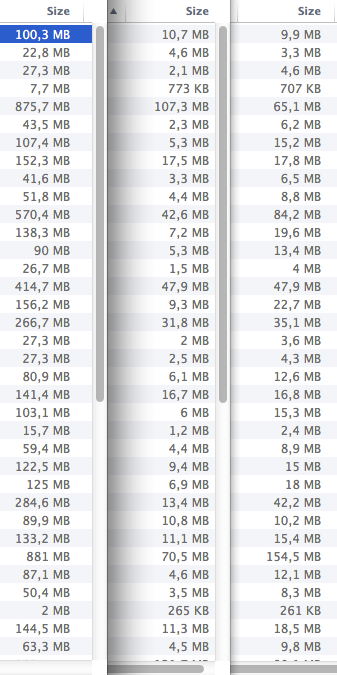
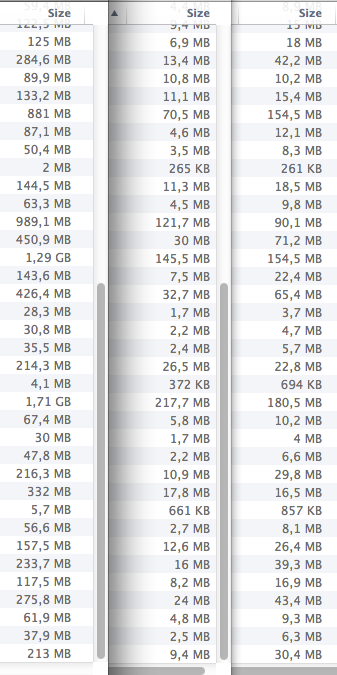
(61 files, from 12.71 GB to 1.2 GB to 1.6 GB)
After OCR is done (keep in mind to select the correct language) you can read the books is “well-enough” quality and easily copy and paste interesting passages. A few books (about 1 of 20) has some OCR problems, and perhaps 1 in 50 is unusable for OCR.
But most of the time it works brilliantly.
I still have my books without them taking up any (relevant) space.
Happy reading 🙂
“I still have my books without them taking up any (relevant) space.”
Yes, but does the author of those books have any of your money for laboring to write the book that you perhaps borrowed before OCRing?
When I OCR a book, I cut of the spine and send it through a document scanner — afterwards the book is pretty much “kaput”. So, yeah, the author got the full price of the book — or, in cases I prefer, the original buyer got some of his/her money back when I bought a used book. OCRing a book that is borrowed would mean (for me) unfolding every page manually and pressing a scan button on a copier/scanner. Possible, and I did do this when I was a student assistant (good thing I had a notebook then and spend the time watching videos), but I would not do this today.
In short, everything I put through my document scanner I have bought in one way or the other, and the book is removed from circulation. 🙂
Thanks for the post. Do you automate the process in any way? I’ve been trying to figure out how to get Acrobat to open any documents that go into a specific folder, run its reduce file size mojo, ocr, and then save it in a new file. Still haven’t figured out how.
No, not really, although I am sure there are ways to do so. Probably via Apple Script or via external programs.
The only thing I do is to use the “Documents” — “Reduce File Size” and “Documents” — “OCR Text Recognition” — “Recognize Text in Multiple Files Using OCR …” to do it in batches. You can select multiple files at once and determine the new file name. I use another folder and add _rdx for reduced file size files and _ocr for text recognition files, ending up with author_year_rdx_ocr. I usually first reduce the file size of all scanned books over night, then using OCR also over night if possible. With OCR, I first sort the files into German vs. English books to select the correct language (makes a huge difference, given that German has “Umlaute” like ä, ö, ü).
I have no qualms letting my notebook work on processor intensive tasks over night, although I strongly recommend having a smoke detector in one’s bedroom. Not that anything ever happened, but you never know, and it’s the smoke that kills you, not the fire.