«You know,» said Arthur, «it’s at times like this, when I’m trapped in a Vogon airlock with a man from Betelgeus, and about to die of asphyxiation in deep space, that I really wish I’d listened to what my mother told me when I was young.»
«Why, what did she tell you?»
«I don’t know, I didn’t listen.»
Douglas Adams from «The Hitchhiker’s Guide to the Galaxy»
Okay, Whisper Transcription is cool. Transforms audio files into text files of what was said. Not perfect, but close.
And it opens up … options. 🙂
I have used screenshots to «bookmark» interesting parts in podcasts. Just take the smartphone, press volume up and on/off at the same time, it takes a picture of the screen. Given that the podcast app (“Book Player”) is shown on the login screen, including the current time code (time in, time remaining), you don’t even need to unlock the device.
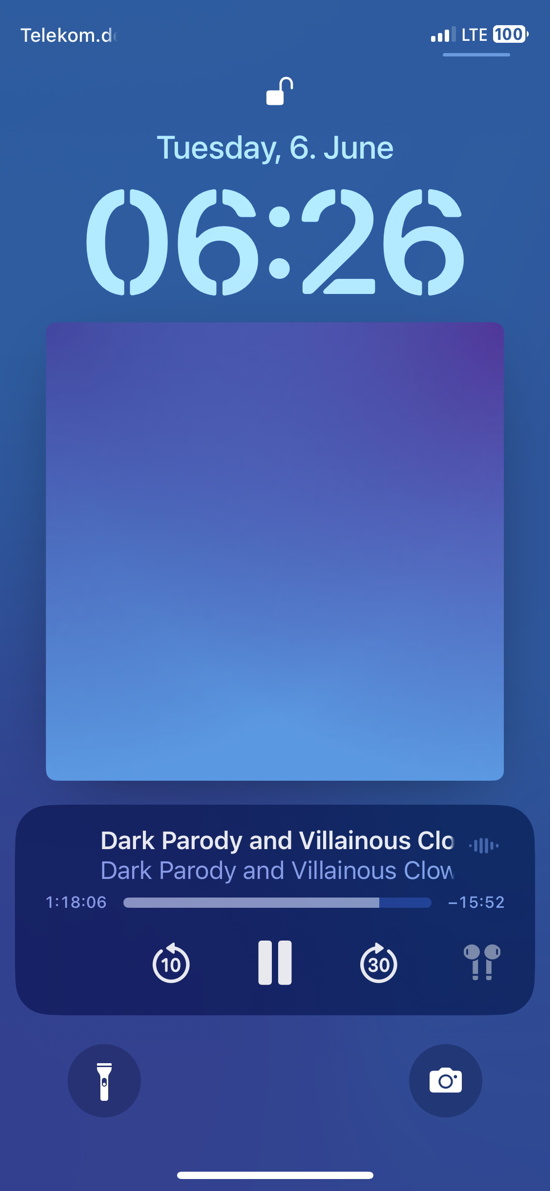
Same when watching videos on the Mac, just press cmd + shift + 4, press space, go over the vlc player and left click. Takes a screenshot including the time information (per default, time left, but does not really matter).

Very convenient to bookmark, but not useful when it comes to getting the interesting quotations. With over 340 bookmarks, transcribing the sections manually is out of the question.
But it is possible to automate the process.
1. Get the file names and time codes
The «bookmarks» are screenshots, i.e., images. Turn them into one PDF file (e.g., via PDF Expert), crop all the pages at the same time so only the Book Player on the Login Screen is visible. Take care that only the name of the episode and the first timecode is shown. Then run OCR. Copy everything to a text file.
You get most of the needed information, incl. the file name (or the internal name) and the time code. Create a .tsv out of it (tab separated file, tab is easier to press than comma or semicolon). I could have automated it, but given the possible OCR problems (usually with the title, time codes were nearly perfect) I did it per hand.
Looks, for example, like this
filetitle txttimecode Mass Formation Psychosis 24:20 220920 Alan Dershowitz 13:13 From Wildfire Cancers to Fo 56:06 Eric Metaxas LIVE at NCSC 28:26 Eric Metaxas LIVE at NCSC 33:28
2. Find the original audio/video files
I used R to list all files on a large drive that archives most of the media files (I prefer to download YouTube videos, podcasts, etc. — depending on the topic, they vanish so quickly). Then the R script did try to identify them based on the OCR of the title.
totalFiles <- c(list.files("EXTERNALDIRECTORYAUDIO", full.names = TRUE, recursive = TRUE), list.files("EXTERNALDIRECTORYVIDEO", full.names = TRUE, recursive = TRUE))
cutTable$deepLink = ""
for(i in 1:nrow(cutTable)) {
findMe <- cutTable[[i, "filetitle"]]
if(sum(str_detect(totalFiles, cutTable[[i, "filetitle"]])) > 0) {
cutTable[[i, "deepLink"]] <- totalFiles[(str_detect(totalFiles, cutTable[[i, "filetitle"]]))][[1]]
} else { cutTable[[i, "deepLink"]] <- NA }
}
Roughly 2/3 were found this way, the others posed a problem, mostly due to the podcast title being shown, not the file name. Given that this was mostly a proof of concept, I focused on the 2/3s.
R created a table that combined the original .tsv with the path and file name info. I removed the entries for which no file could be found (saved them separately for later).
3. Determine how much you want to cut
In order to limit the amount of audio that needs to be transcribed (takes ages, resource heavy, no need to read the whole thing just for one nugget), I used the time code and subtracted 3 minutes from it (or added three minutes if the time code was showing the amount of time left, as in some vlc screenshots). Went into a table column in the 00:00:00 format (hours:minutes:seconds). I used a standard default of 6 minutes trim duration, giving me three minutes before the bookmark and three minutes after the bookmark. It’s a guess, might change it later.
Code not shown because it is atrociously written (had some problems with lubridate). However, it worked.
4. Use ffmpeg to cut the relevant sections
I found the necessary code online ( https://shotstack.io/learn/use-ffmpeg-to-trim-video/ , https://superuser.com/questions/138331/using-ffmpeg-to-cut-up-video ) and used R to go through each line in the table, get the relevant information (empty spaces in paths/file names masked with backslash) and used the ffmpeg command to cut the relevant sections. I took care to simply copy the sections, not to re-encode them. Cutting over 240 videos was done in a matter of minutes.
for(i in 1:nrow(workData)) {
target <- str_replace_all(workData[[i, "targetName"]], " ", "\\\\ ")
link <- str_replace_all(workData[[i, "deepLink"]], " ", "\\\\ ")
cutTime <- workData[[i, "finalCutTimeMinusTwo"]]
startBack <- workData[[i, "startFromEnd"]]
if(startBack) {
print(paste0("ffmpeg -sseof -", cutTime, " -i ", link, " -t 00:06:00 -c copy ~/Desktop/cuts/", target))
system(paste0("ffmpeg -sseof -", cutTime, " -i ", link, " -t 00:06:00 -c copy ~/Desktop/cuts/", target))
}
if(!startBack) {
print(paste0("ffmpeg -i ", link, " -ss ", cutTime, " -t 00:06:00 -c:v copy -c:a copy ~/Desktop/cuts/", target))
system(paste0("ffmpeg -i ", link, " -ss ", cutTime, " -t 00:06:00 -c:v copy -c:a copy ~/Desktop/cuts/", target))
}
}
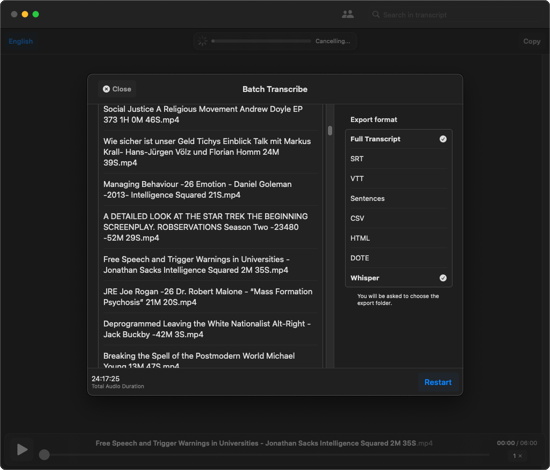
Use Whisper Transcription to transform the cuts into text files
That part will take ages — but with the pro version, you can use batch processing. Just drag the cuts into Whisper and select the output formats. I use Full Transcript (creates a text file) and Whisper (to quickly listen in if I think I detect errors in the transcription).
Probably best to let it run over a couple of days/nights. However, Whisper is extremely resource heavy and does not prevent sleep mode:

So you might want to deactivate that the Mac goes to sleep automatically.
And as usual, without warranty.