«Where there’s a will, there’s a way. And a maniac is matchless for invention.»
Marquis de Sade in «Quills»
With 1260 kindle books — well, I like books, they never let me down — there is the problem that one day, they might no longer be available. Sure, Amazon is a big company, but bigger ones have folded. Apparently — so I have heard — there are ways to bypass the digital rights management (DRM) restrictions. But there are also changes by Amazon that make it increasingly difficult. Things like forcing updates, otherwise books published in 2023 cannot be downloaded anymore. With the new software having better DRM protection.
While they can make things difficult, I doubt they can completely prevent people from bypassing it. Even if people end up using … well, manic strategies.
After all, you could simply put a Kindle device — or any screen on which the Kindle App is running — on a xerox machine, or heck, even just use a camera to take photos of the pages. Anything you see the camera can see. Quality might suffer and it would be a pain in the ass to make a PDF out of it, but it would work.
There might even be a faster version. It might be possible to simply automate taking screenshots of the app, e.g., on a Mac. After all, Mac comes with automator. It would be possible to record mouse movements and clicks to record flipping the pages. Even if you’d go from the last page to the first, for some reason. Combined with taking a screenshot and renaming it to date and time (incl. seconds), and adding a loop, it would simply take a screenshot, flip the page, take a screenshot, flip the page, etc. You’d have to guess the number of pages for the loop, which might differ from what is shown in the Kindle app.
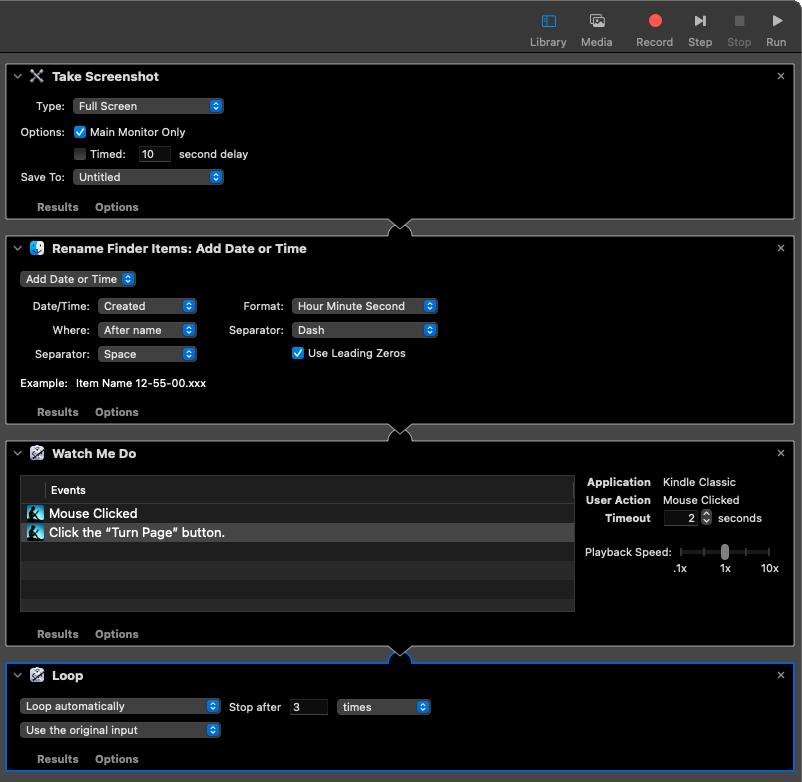
If that would work, neither saying it does nor recommending/condoning it. It’s a … uh, thought experiment. And of course, you could use an app like GraphicConverter to cut the screenshots to size (with File => Auto Convert … and using Crop Region). Sorting them from first to last page in Finder (if named by date and going from last to first page, sorting descending by name or creation date) then renaming it via Finder => Rename => Format => Name and Index, you would get the pages with nice filenames. That would make it easy to use, e.g., PDF Expert and File => Merge Files … and put them all in a PDF. Then it would only require an App like DEVONthink for OCR (PDF Expert is not as good). Afterwards perhaps PDF Expert’s Reduce File Size.
Yeah, that might work and would be one way to bypass the DRM on Kindle. Again, as a thought experiment. Might be nicer on the thumb than using an iPad and do screenshots manually, as possible way to by pass DRM. If anyone would do it — which I do not recommend.
But yeah, just a thought.